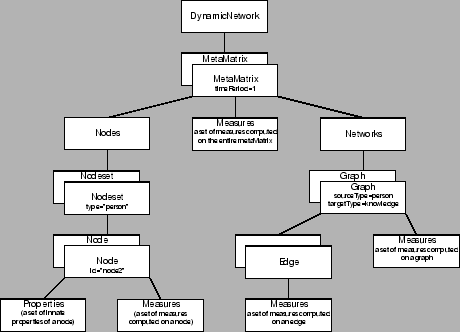
|
DyNetML examples can be found here:
For more tools, please refer to CASOS tool section.
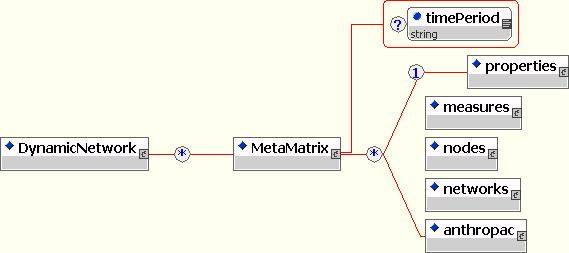
The <DynamicNetwork> element encapsulates all time periods within a dynamic network.
Each time period is represented by a <MetaMatrix> element, which encapsulates network data for a single time period, including multiple matrices and node and properties. Optional ``timePeriod'' attribute identifies the time at which a given metamatrix has been collected.
Optional <measures> element encapsulates a set of MetaMatrix-level measures that have been computed on the given time period.
<measure name=''sampleMeasure'' type=''double'' value=''1''>
Each measure is specified with a unique name, type (double, string, boolean) and value
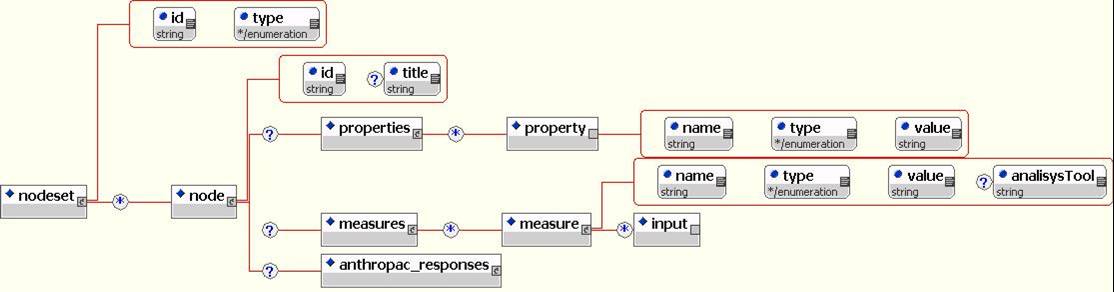
<nodes> element encapsulates all of the nodesets in a given MetaMatrix.
<nodeset id=''nodeset1'' type=''agent''>
A nodeset is a grouping of nodes by type; types include agent, knowledge, resource, task, organization, location. More the one nodeset of the same type can be defined; nodeset ID must be unique.
Each <node> within a <nodeset> has to be supplied with a unique ID and can contain an arbitrary number of innate <properties> or computed <measures>. This allows the data collectors to specify arbitrarily complex data about nodes while separating collected data from results of analysis.
The <networks> element encapsulates network data stored as graph connection lists.
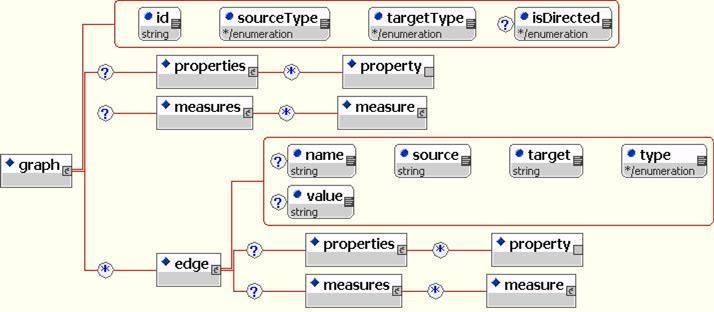
The <graph> nodes are specified with a unique ID and IDs of the source and target nodesets. Each Graph contains a collection of Edge elements whose source and target are nodes previously declared in a Nodeset.
This allows the user to specify an arbitrary number of networks involving the same (e.g friendship and advice networks) or different types of actors (e.g. communication and resource distribution networks).
<edge source=''node1'' target=''node2'' type=''double'' value=''1''>
Edges are represented by specifying the source and target of the edge. Each edge also has a value
and a value type (double, string or boolean).
Each graph and edge can also be followed by a set of innate Properties and computed Measures.
For more information, please refer to the Document Type Definition (DTD) and a sample dataset in the appendix of this paper.
In our vision, the future of social network analysis lies in creating a seamless toolchain, enabling researchers to mix and match data gathering, analysis and visualization tools and to create analysis scripts for batch-mode processing of large datasets or for repeating the same analysis on different datasets. Publishing analysis scripts would allow the research community to more easily reproduce and verify experimental or empirical results.
Each of the tools on the toolchain shall:
An integrated toolchain such as the one outlined above can only be created through cooperation of members of the research community through an open-source development process, but the first step is to create a uniform data interchange language. In this paper, we proposed one such language: DyNetML, an XML-derived language for specification of rich social network data.
It is important to note that since DyNetML is intended as a service to the social network analysis and simulation community, comments and requests for revisions are welcome at any time. Once the project has considerable community support, we shall establish a revision process that will respond to the requirements of the community while maintaining backward compatibility with existing software.
About this document ... DyNetML: Interchange Format for Rich Social Network Data
This document was generated using the LaTeX2HTML translator Version 2002 (1.62)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 paper.tex
The translation was initiated by Maksim Tsvetovat on 2003-08-03