A Social-Event Based Approach to Sentiment Analysis of Identities and Behaviors in Text
Overview | People | Collaborators | Sponsors | Publications | Tools
Joseph, K. & Wei, W. & Benigni, M. & Carley, K.M. A social-event based approach to sentiment analysis of identities and behaviors in text. Accepted with minor revisions: Journal of Mathematical Sociology.
Abstract:
In this work, we focus on the development of a method to better understand biases, or prejudices, of others and how we might learn these from real-world data. We ask, given a large corpus of text, how can we determine prejudices that the individuals or agencies who have written the text might hold? More specifically, we were interested in prejudices towards specific identities, which are, roughly, the labels we use for different categories or groups of people.
Such a question falls roughly under the methodological domain of aspect-level sentiment mining, where the goal is to determine sentiment towards a particular concept within a particular text or set of texts. While approaches to aspect-level sentiment mining are ever-improving and increasingly complex, most still rely at some level on well-known valence words (e.g. 'good', 'bad') or on explicit signals of sentiment in web data (e.g. movie ratings). In contrast, we believed that what was needed was a new, theoretically driven methodology, one that relied on what we already knew about prejudice, culture and social interaction. While sociology and psychology give us a never-ending supply of theory and methods related to identity, only Affect Control Theory provides both a numeric representation of sentiments held towards identities and a mathematical model for how this sentiment can be inferred from social events (events where one identity enacts a behavior on another).
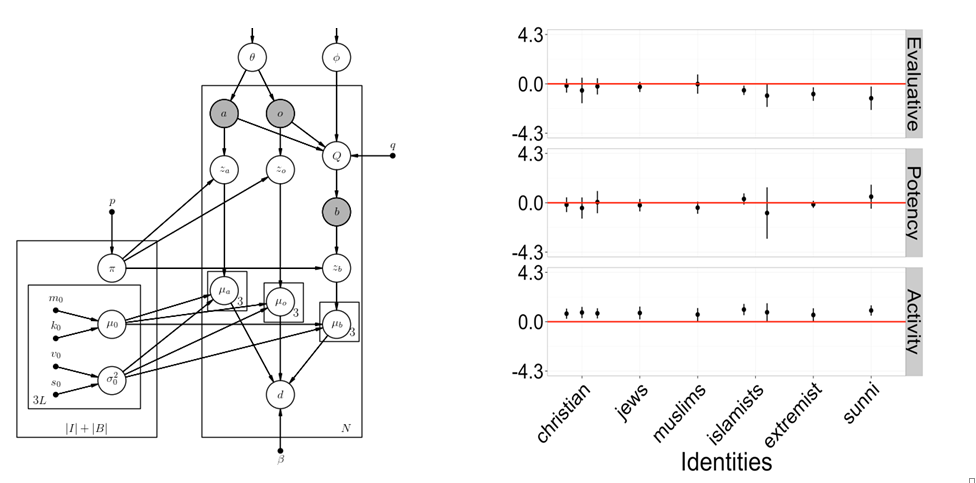
We developed a novel method that combines the mathematics of ACT with a semi-supervised, Bayesian Network-based learning approach. After extracting social events from text using common heuristics from a dependency parse of the data, we used this model to “learn” prejudices held towards identities. The model performed well on predictive experiments, and when we ran it on a corpora of newspaper data relevant to the Arab Spring, we found that more specific Muslim identities, in particular the Sunni identity, were viewed significantly more negatively in the text than the generic Muslim identity.