Exploring Patterns of Identity Usage in Tweets: A New Problem, Solution and Case Study on Ferguson
Overview | People | Collaborators | Sponsors | Publications | Tools
Joseph, K., Wei, W. & Carley, K.M. (in submission). Exploring patterns of identity usage in tweets: a new problem, solution and case study on Ferguson, WWW 2016.
Abstract:
Sociologists have long been interested in the ways that identities, or labels for people, are created, used and applied across various social contexts. The present work makes two contributions to the study of identity, in particular the study of identity in text. We first consider the following novel Natural Language Processing (NLP) task: given a set of text data (here, from Twitter), label each word in the text as being representative of a (possibly multi-word) identity. To address this task, we develop a comprehensive set of indicators that leverages several avenues of recent NLP work on Twitter. We then use these indicators to build a classifier that takes in a Tweet and returns the words within the tweet that represent identities (i.e. 'professor' in the tweet 'I hate my professor').
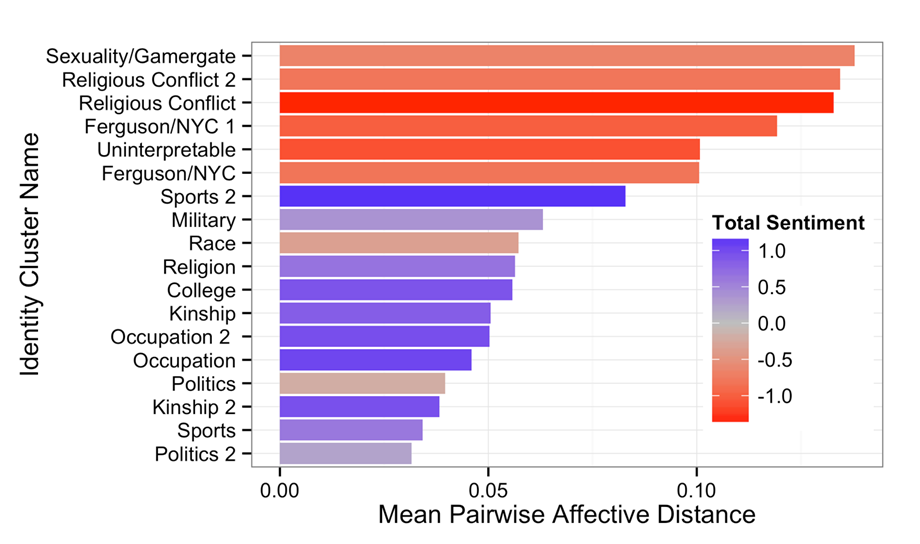
We then use our model for a case study, applying it to a large corpora of Twitter data from users who actively discussed the Eric Garner and Michael Brown cases. As shown in the figure above, we find that identities cluster into semantically coherent groups, i.e. those that are related to the military, and that people in our data have vary different sentiments towards these different clusters of identities. Further, we observe that the identities used by individuals differ in interesting ways based on social context measures derived from census data. Specifically, we observe a positive association between the percentage of people in a users home county that are African American and her use of racial identities on Twitter.